Introduction
Sanzu is a platform designed to solve a common problem faced by users of large language models (LLMs): organizing conversations from multiple LLMs into a single, queryable space. As someone who uses LLMs daily—ChatGPT for general questions, Claude for detailed analysis, and Grok for unique perspectives—I often found it challenging to manage conversations scattered across different platforms.
For example, if I’m researching workouts and have related conversations on ChatGPT, Claude, and Grok, I’d have to manually search each platform to revisit them. Sanzu addresses this by creating RAG(Retrieval Augmented Generation) allowing users to aggregate conversations into categorized projects (e.g., "Workouts"), store them efficiently, and query them to get tailored responses combining insights from all LLMs.
In this project report, I’ll walk you through what Sanzu is, its technical architecture, the system design, challenges faced during development, and future improvements I plan to implement.
You can also check out the demo video for a live walkthrough of the platform.
Project Overview
Sanzu lets users organize conversations from multiple LLMs into projects based on topics. The core workflow is simple:
- Add Conversations: Users share a conversation link (e.g., a ChatGPT chat link) with Sanzu. The platform scrapes the conversation, generates embeddings using Ollama, and stores them in a Qdrant Vector DB.
- Organize into Projects: Conversations from different LLMs are grouped into projects (e.g., "Workouts") based on their content.
- Query Projects(RAG): Users can query a project with a question (e.g., "What’s a good beginner workout routine?"), and Sanzu retrieves relevant conversation data from Qdrant using Similarity search, processes it with Ollama, and generates a tailored response.
Here’s the polished definition I used in my demo:
🔗 Share Conversation Link
→ Accept URL input (ChatGPT thread)
→ Validate and extract content
🧹 Scrape & Clean
→ UsedBeautifulSoup,Playwrightto scrape content
📦 Store in Qdrant
→ Generate embeddings (Ollama)
→ Store chunks with metadata (source,timestamp,tags)
→ Enable fast vector + metadata search
🗣️ Query
→ Embed user question
→ Use same embedding model as ingestion
🔍 Similarity Search in Qdrant
→ Retrieve top-k relevant chunks
🛠️ Generate Response (LangChain + Ollama)
→ LangChain RAG chain → Inject query + chunks into Ollama (llama3)
→ Return answer (streamed or complete)
Technical Details
Sanzu is built using a microservices architecture, with each component running in a Docker container for easy management and deployment. Below is the project structure, as shown in the first diagram:
Docker Setup
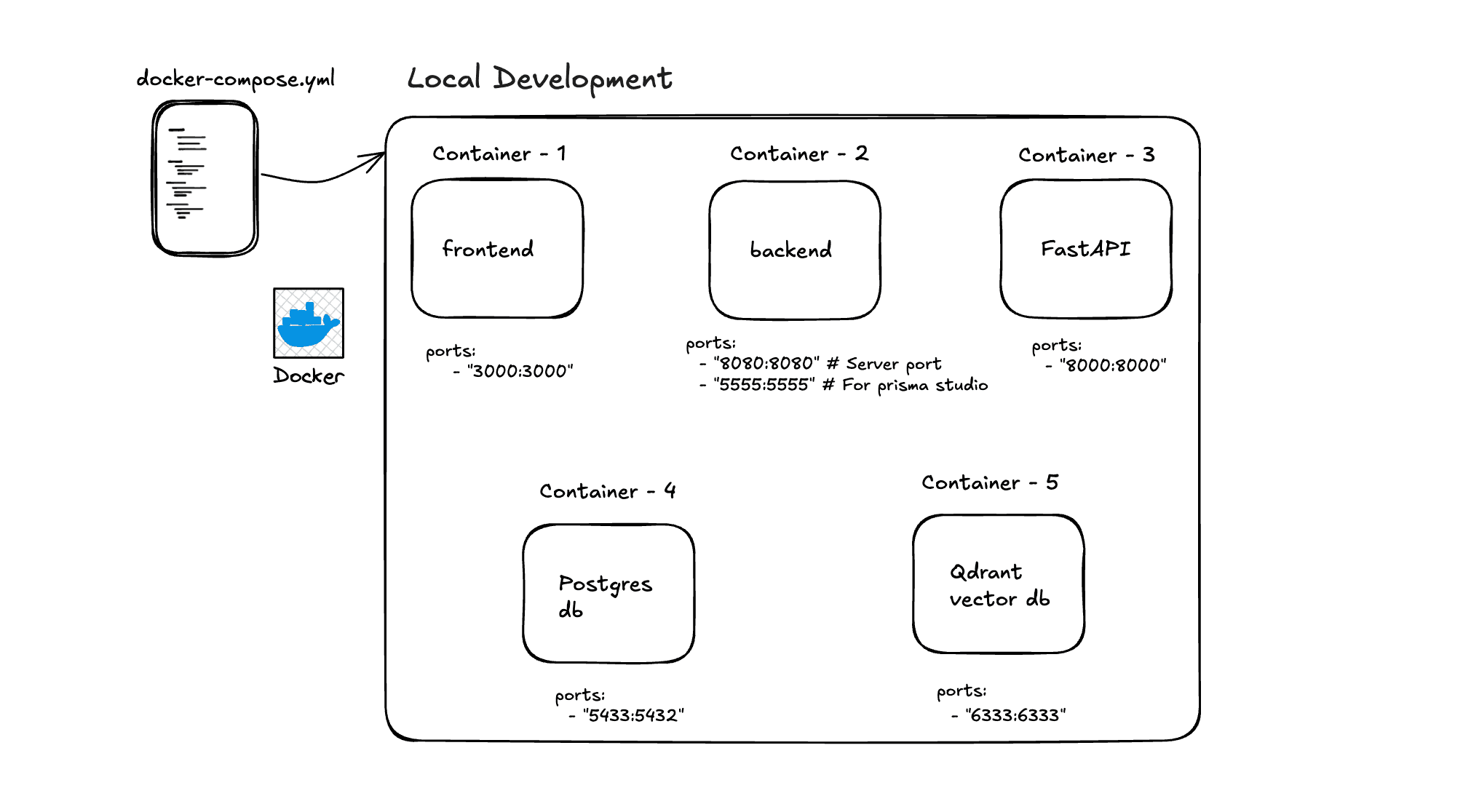
Project Directory Structure
The project directory mirrors the container setup:
frontend/: Contains the Next.js app with ShadCN for the user interface.backend/: Houses the Express server with Prisma for database management.fastserver/: Includes the FastAPI service with modules for scraping (using Playwright and Beautiful Soup), embedding generation (using LangChain and Ollama), and querying.
Directory structure:
└── harshptl14-sanzu/
├── docker-compose.yml
├── backend/
├── fastserver/
└── frontend/
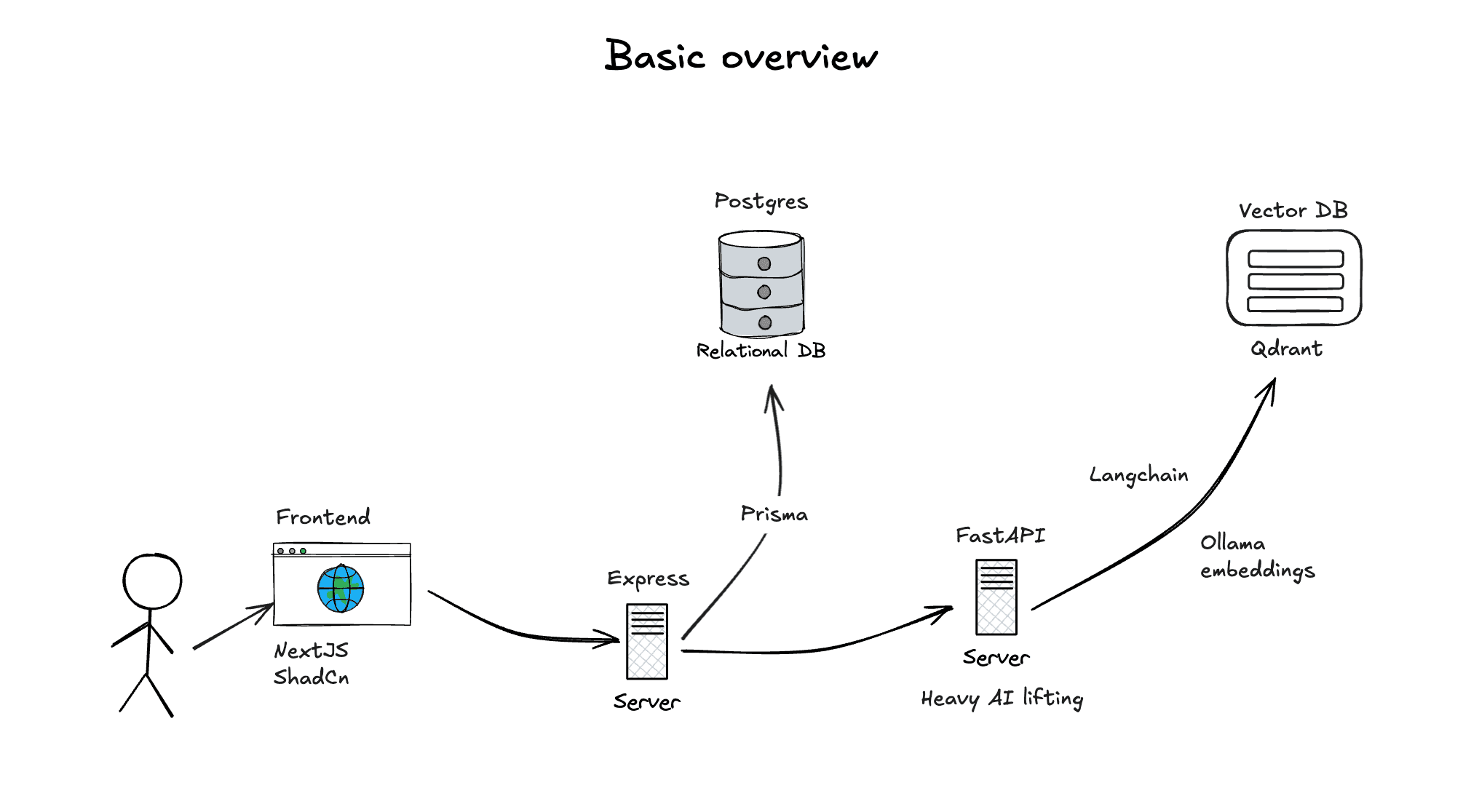
System Design
The system design illustrates how the components interact to deliver Sanzu’s functionality. The second diagram provides a high-level overview:

Workflow
-
User Interaction:
- The user interacts with the Frontend (Next.js + ShadCN) through a browser.
- They share a conversation link (e.g., a ChatGPT chat link) via the frontend interface.
-
Backend Processing:
- The Frontend sends the conversation link to the Backend (Express).
- The backend uses Prisma to store project metadata (e.g., project name, conversation IDs) in the Postgres Relational DB.
- The backend forwards the conversation link to the FastAPI Server.
-
AI Processing:
- The FastAPI Server uses its Scraping Service (Playwright and Beautiful Soup) to scrape the conversation content from the link.
- LangChain and Ollama generate embeddings (numerical representations of the text) for the scraped conversation.
- The embeddings are stored in the Qdrant Vector DB, along with metadata linking them to the project.
-
Adding More Conversations:
- The same process repeats for conversations from other LLMs (e.g., Claude, Grok). They are scraped, embedded, and stored in Qdrant under the same project.
-
Querying:
- The user queries a project (e.g., "What’s a good beginner workout routine?" for the "Workouts" project).
- The Frontend sends the query to the Backend, which forwards it to the FastAPI Server.
- FastAPI uses its Query API to search the Qdrant Vector DB for relevant embeddings in the project.
- LangChain and Ollama process the retrieved data to generate a tailored response.
- The response is sent back to the Frontend for the user to view.
Key Technologies
- Next.js: Framework for building the frontend with React.
- ShadCN: UI component library for a consistent design.
- Express: Backend framework for handling API requests.
- Prisma: ORM for interacting with the Postgres database.
- FastAPI: Python framework for AI tasks like scraping and embeddings.
- Postgres: Relational database for structured data.
- Qdrant: Vector database for storing and retrieving embeddings.
- LangChain: Framework for working with LLMs, handling embeddings and context.
- Ollama: Tool for running open-source LLMs locally to create embeddings and process queries.
- Playwright & Beautiful Soup: Tools for scraping conversation content from LLM links.
- Embeddings: Numerical representations of text for similarity search.
Challenges Faced
During development, I encountered several challenges:
-
Scraping Conversations:
- Scraping conversation links from LLMs like ChatGPT and Claude was tricky due to dynamic web content and authentication requirements. I used Playwright and Beautiful Soup to handle this, but ensuring consistent scraping across different platforms required extensive testing.
-
Embedding Generation:
- Generating embeddings with Ollama and LangChain was computationally intensive. I had to optimize the process to avoid performance bottlenecks, especially when handling large conversations.
-
Vector DB Integration:
- Integrating Qdrant for vector storage and retrieval was new to me. I faced issues with indexing and querying embeddings efficiently, which required tweaking Qdrant’s configuration and learning its best practices.
-
Docker Orchestration:
- Managing multiple containers with Docker Compose was complex, especially ensuring that all services (frontend, backend, FastAPI, Postgres, Qdrant) communicated correctly. I had to debug networking issues and ensure proper port mapping.
Future Improvements
Sanzu is still in its early stages, and I plan to add several features in the future:
-
Support for More LLMs:
- Currently, Sanzu supports ChatGPT, Claude, and Grok. I’d like to add support for other LLMs like LLaMA, Mistral, and Gemini to make the platform more versatile.
-
Improved Scraping:
- Enhance the scraping service to handle more complex conversation formats and improve reliability across different LLM platforms.
-
Advanced Querying:
- Implement more sophisticated query processing, such as supporting natural language filters (e.g., "Show me conversations from ChatGPT only") or multi-step reasoning.
-
User Authentication:
- Add user authentication and authorization to allow multiple users to create and manage their own projects securely.
-
UI Enhancements:
- Improve the frontend with more interactive features, such as visualizing conversation embeddings or providing a detailed project overview.
Demo Video
Check out the live demo of Sanzu in action! In the video, I walk through creating a project, adding conversations from ChatGPT and querying the project to get tailored responses.
Conclusion
This is the problem that I personally faced, and tried to solve it. While the platform is still in its early stages, I’m excited to continue working on it and adding more features to make it even more powerful, and maybe one day ship it to production and you can use it too!!
Thanks for reading! If you have any feedback or suggestions, feel free to reach out.